



Trainieren Sie Ihre IDP-Modelle für die automatisierte Klassifizierung und Trennung direkt in DocuWare – mit Ihren Dokumenten direkt aus dem DocuWare Archiv. Das geht im Nu und einfacher als je zuvor.
Inhalt
- Schnelles und unkompliziertes Modell-Training
- So funktioniert es
- Automatische Dokumententrennung bei Scan und Import
- Schon in Vorbereitung: Noch mehr Möglichkeiten
Schnelles und unkompliziertes Modell-Training
Ihre Trainingsdokumente können Sie bequem direkt aus Ihren DocuWare Archiven auswählen und das Training gleich innerhalb der DocuWare Oberfläche starten. Bisher mussten Dokumente für das Training der Modelle manuell auf die dedizierte IDP-Plattform hochgeladen werden.
So funktioniert es
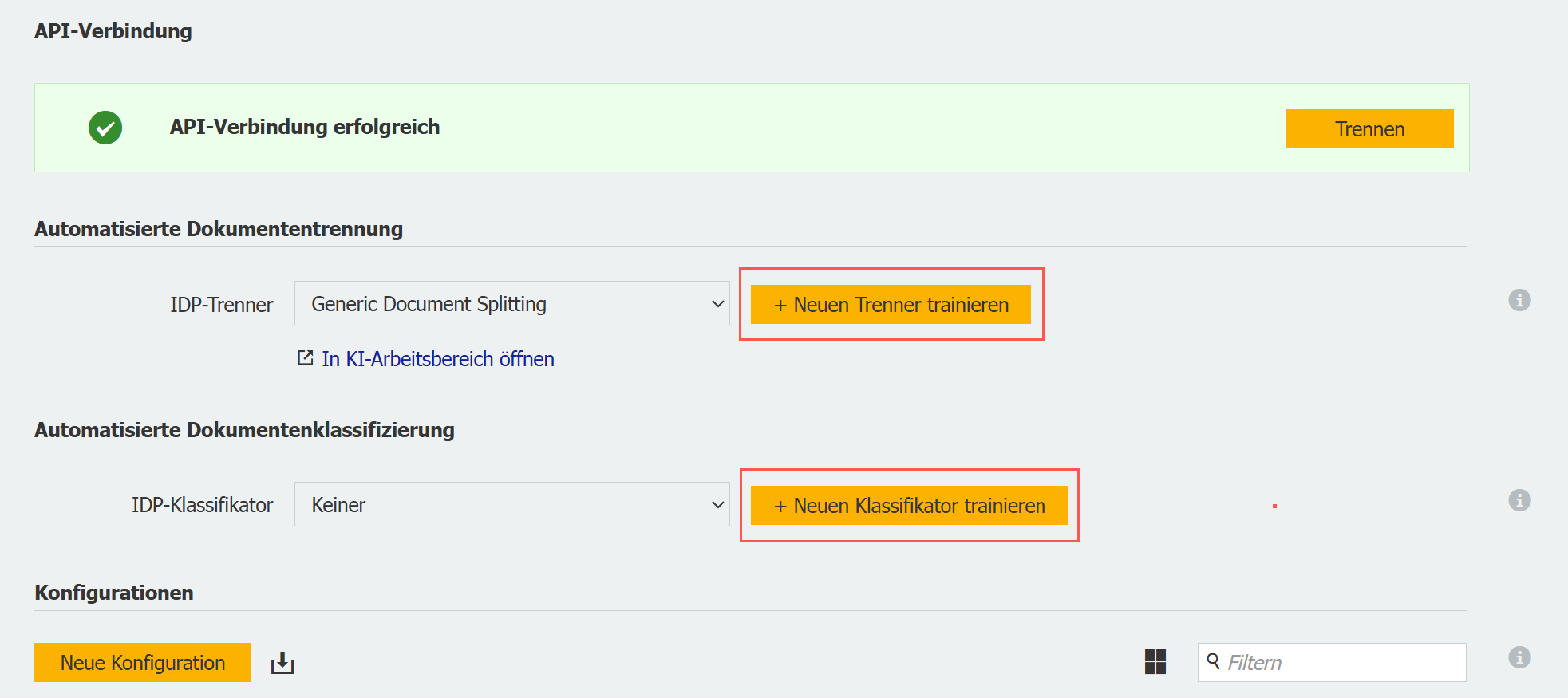
In der DocuWare Konfiguration starten Sie im Bereich IDP das Training von neuen Trennungs- und Klassifizierungsmodellen.

Über ein übersichtliches Dialogfenster werden Sie Schritt für Schritt durch das Training geführt. Eine Auswahlliste Ihrer DocuWare Archive hilft Ihnen, gezielt die passenden Dokumente für das Training auszuwählen:

Um einen neuen Trenner zu trainieren, wählen Sie mindestens ein Archiv aus.

Für das Training eines Klassifikators wählen Sie mindestens zwei verschiedene Archive. Das System zeigt Ihnen an, ob ausreichend Dokumente für ein erfolgreiches Training vorhanden sind.
Das Modelltraining läuft automatisch im Hintergrund und dauert bis zu 24 Stunden. Sie können bei Bedarf mehrere Trainingsprozesse gleichzeitig starten – sobald ein Training läuft, können Sie das nächste anlegen.
Automatische Dokumententrennung auch bei Scan und Import
Übrigens können Sie auch mit der Integration von IDP in die DocuWare Desktop Apps PDF-Stapeldateien beim Scannen oder Importieren automatisch in einzelne Dokumente aufteilen lassen.
Sie scannen beispielsweise alle Lieferscheine des Tages in einem Schritt ein, und DocuWare trennt die Dokumente automatisch, sodass jedes einzeln weiterverarbeitet werden kann. So sorgen Sie dafür, dass Ihre Daten ohne Umwege direkt den richtigen Prozessen zugeführt werden. Mehr Informationen dazu finden Sie im DocuWare Knowledge Center.
Schon in Vorbereitung: Noch mehr Möglichkeiten
Wir arbeiten bereits daran, Ihnen bald auch das Training von Extraktionsmodellen direkt in DocuWare bereitzustellen. In Kürze wird es zudem möglich sein, beim Klassifizierungs-Training nicht nur Archive, sondern auch spezifische Indexfelder auszuwählen. Dadurch können verschiedene Werte eines Indexfelds automatisch als eigene Klassen erkannt und trainiert werden.