



Automatic document indexing eliminates monotonous data entry as the self-learning service automatically recognizes key information in documents and uses it for indexing. With these tips, you can start the turbo for the correct capture of index data.
Intelligent Indexing is based on machine learning. As soon as you correct an index value, the service learns from your feedback and the indexing quality increases with each additional document.
To ensure that the service delivers the best possible results, you should follow these tips:
1. Better to Click than TypeIntelligent Indexing learns through your corrections. Generally you should consider: When entries are coming through incorrectly or incompletely, don’t use the keyboard to make corrections in Intelligent Indexing, but use the One Click Indexing feature. Otherwise the service won’t learn to find the right data from the document and will instead rely on manual entry for subsequent documents.
Here’s how it works:
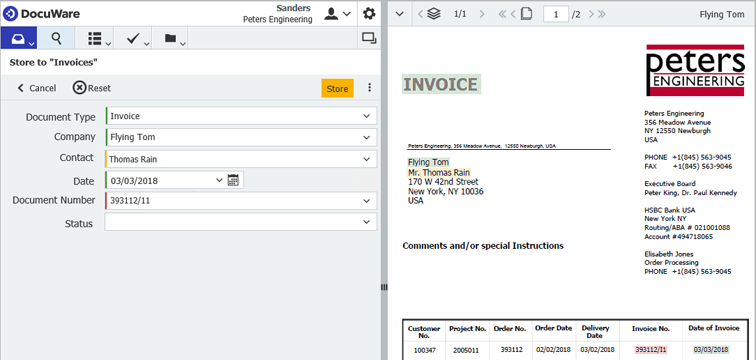
- In the store dialog, click in the insufficiently filled index field – the source for the index entry in the document will be highlighted.
- Now press on the mouse key and mark the correct or complete text in the document. It will immediately be transferred into the store dialog.
- You can now store the document. Intelligent Indexing not only remembers the correct term, but also its position. Already with the next corresponding document the tremendously clever service indexes correctly.
The accuracy of Intelligent Indexing largely depends on a document‘s legibility. We therefore recommend scanning a document with a minimum resolution of 300 dpi. Otherwise it’s easy for so-called OCR mistakes to occur. Common examples: the system can‘t differentiate between "i" or "!" or "I"; or it turns a "w" into two "v".
Again, it’s best to correct these reading errors with One Click Indexing. Manual entries should really be the last resort – only to be used if you cannot capture the right information from the document. If you are noticing several OCR errors, then you might want to first adjust the resolution in your scan settings.
3. Just like kids: Don't teach anything wrong in the first placeIntelligent Indexing learns from the index data of a document when it is stored. However, if this index data is wrong, Intelligent Indexing will be taught to extract incorrect values.
A simple example: Three colleagues store documents within a DocuWare system. The first colleague enters the gross amount of the invoices in the index field "Invoice amount," the second colleague enters the net amount instead, and the third colleague enters nothing at all in the field. In this situation, Intelligent Indexing has no way of learning which values are needed as index data.
You also should know: If for some reason a document was indexed and stored incorrectly with Intelligent Indexing, you may have to correct the entry a few times in order for the service to unlearn its previous choice and work correctly going forward.
And here are a few tips for configuring Intelligent Indexing
